
MLC-LLM으로 iOS에서 로컬 LLM 실행하기
목차
MLC-LLM을 활용하여 iOS 기기에서 로컬 LLM을 실행하는 방법을 공유합니다.
👉 English Version
MLC-LLM
MLC-LLM은 기계 학습 모델을 모든 하드웨어 장치(모바일, 브라우저, 데스크톱 등)에서 범용적으로 배포하고 고성능으로 실행할 수 있도록 돕는 솔루션입니다. 특히 iOS 환경에서는 Metal API를 활용하여 하드웨어 가속을 지원하므로, 상대적으로 사양이 낮은 모바일 기기에서도 LLM을 효율적으로 돌릴 수 있습니다.
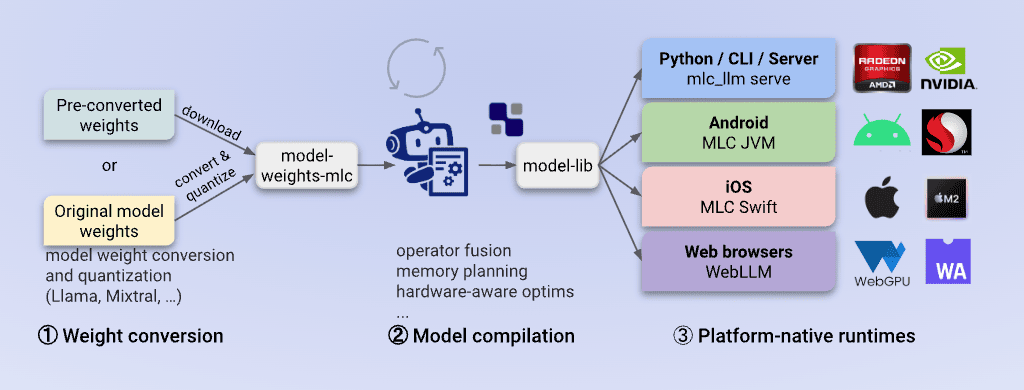 MLC-LLM (출처)
MLC-LLM (출처)이번 포스팅에선 MLC-LLM을 활용하여 iOS 기기에서 로컬 LLM을 실행하는 방법을 공유하겠습니다.
초기 세팅
먼저 MLC-LLM 프로젝트를 클론합니다. 이 프로젝트는 핵심 컴파일 엔진인 TVM Unity 등을 서브모듈로 포함하고 있으므로, --recursive 옵션을 사용하거나 클론 후 서브모듈 업데이트를 반드시 진행해야 합니다.
1 | git clone https://github.com/mlc-ai/mlc-llm.git |
다음으로 LLM 컴파일 및 모델 변환을 위한 Python 가상 환경을 구축합니다. MLC-LLM은 모델을 기기에 최적화된 코드로 변환하는 과정이 필요한데, 시스템 환경과의 충돌을 방지하기 위해 가상 환경 사용을 권장합니다. 특히 mlc-llm-nightly 패키지는 빈번하게 업데이트되므로 pre-built된 nightly wheel 엔진을 설치하는 것이 가장 효율적입니다.
1 | python3 -m venv .venv |
마지막으로 대용량 가중치 파일 관리와 iOS 성능 가속을 위한 도구들을 설치합니다. LLM 모델은 수 GB에 달하는 가중치를 포함하므로 git-lfs가 필수적이며, iOS 기기에서 Metal GPU를 통해 모델을 빠르게 돌리기 위해 MetalToolchain 구성 요소가 필요합니다.
1 | brew install git-lfs |
빌드 및 실행
이제 설치된 도구들을 이용해 iOS 앱에 포함될 라이브러리를 패키징합니다. 이 단계에서는 앞서 설치한 MLC-LLM 엔진을 iOS 프로젝트가 인식할 수 있는 정적 라이브러리 형태로 묶어주는 과정이 진행됩니다.
먼저, 빌드 스크립트가 소스 코드의 위치를 알 수 있도록 MLC_LLM_SOURCE_DIR 환경 변수를 설정해야 합니다. 일시적으로 적용할 수도 있지만, 추후 편리한 사용을 위해 ~/.zshrc 또는 ~/.bash_profile에 추가하는 것을 권장합니다.
1 | # ~/.zshrc 등에 추가 (경로는 본인의 mlc-llm 클론 경로로 수정) |
환경 변수가 설정되었다면, mlc-llm/ios/MLCChat 폴더로 이동하여 패키징 명령을 실행합니다.
1 | cd ios/MLCChat |
패키징이 완료되면 ios/MLCChat 폴더에 Xcode 프로젝트가 준비됩니다. 터미널에서 다음 명령어를 입력하면 즉시 Xcode가 실행됩니다.
1 | xed . |
Xcode 프로젝트가 열리면 실제 기기나 시뮬레이터에서 실행하기 위한 몇 가지 필수 설정이 필요합니다.
대상 기기(Destination) 설정: 실제 iPhone에서 실행할 수도 있지만,
My Mac (Designed for iPad)옵션을 선택하여 Mac의 실리콘 칩 가속을 활용해 테스트해볼 수 있습니다. Xcode에서 My Mac (Designed for iPad) 설정
Xcode에서 My Mac (Designed for iPad) 설정서명 및 기능(Signing & Capabilities): iOS 앱은 보안 상 반드시 서명이 필요합니다. 본인의 Apple ID 팀을 선택하고,
Bundle Identifier를 파일이 겹치지 않도록 유니크한 값으로 수정해 줍니다.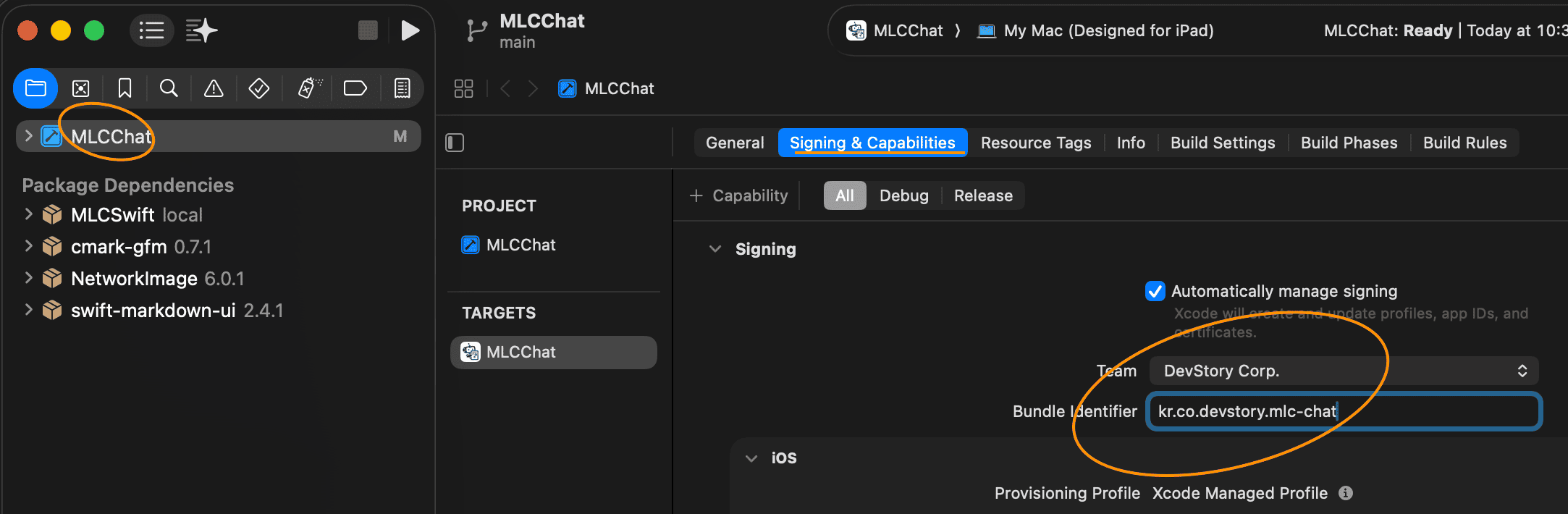 Xcode Signing 및 Bundle Identifier 설정
Xcode Signing 및 Bundle Identifier 설정
모든 설정이 완료된 후 Run(Cmd + R) 버튼을 누르면 앱이 실행됩니다. 초기 실행 시에는 모델 목록이 비어 있으므로, 앱 내의 모델 관리자(Model Manager)를 통해 기본적으로 지원되는 모델들을 다운로드할 수 있습니다.
기본 모델
iOS MLCChat 프로젝트에서 기본적으로 지원하는 모델 구성은 다음과 같습니다.
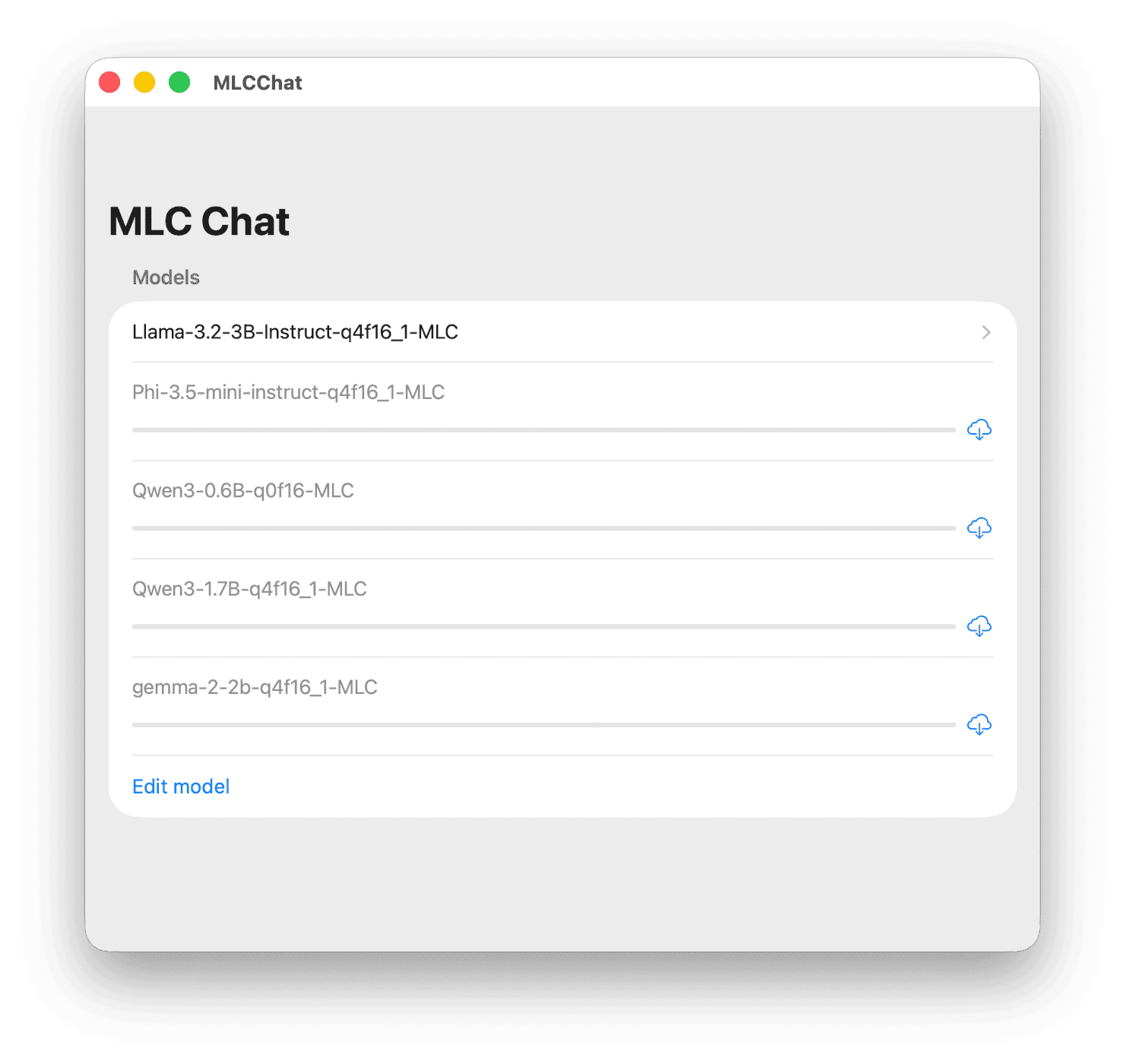 MLCChat 기본 모델 목록
MLCChat 기본 모델 목록| 모델 명 (Model) | 주요 특징 (Characteristics) |
|---|---|
| Llama-3.2-3B | Meta 개발, 최신 고성능 소형 모델, 4비트 양자화, 2K Context |
| Gemma-2-2B | Google 개발, 효율적인 아키텍처, 4비트 양자화 |
| Phi-3.5-mini | Microsoft 개발, 강력한 추론 성능, 4비트 양자화 |
| Qwen3-0.6B | Alibaba 개발, 극도로 가벼운 초경량 모델, FP16 정밀도 |
| Qwen3-1.7B | Alibaba 개발, 밸런스 잡힌 성능, 4비트 양자화, 2K Context |
다음은 구글의 Gemma2 2B 모델을 iOS에서 직접 구동한 시연 영상입니다.
Gemma2 2B 모델 데모
Google에서 공개한 Gemma2 2B 모델은 비교적 가벼운 20억 개의 파라미터를 가졌음에도 불구하고, 최적화된 아키텍처 덕분에 동급 대비 매우 뛰어난 성능을 보여주는 모델입니다.
특히 이번 데모에서 사용한 q4f16_1 양자화 방식은 모델의 가중치를 4비트(q4)로 압축하여 용량을 줄이되, 연산 정밀도는 16비트(f16)로 유지하여 성능 하락을 최소화한 방식입니다. 이러한 최적화 덕분에 모바일 기기의 제한된 RAM 환경에서도 원활한 구동이 가능하며, 실제 실행 시 약 2.4GB 정도의 메모리를 점유하며 안정적으로 동작하는 것을 확인할 수 있습니다.
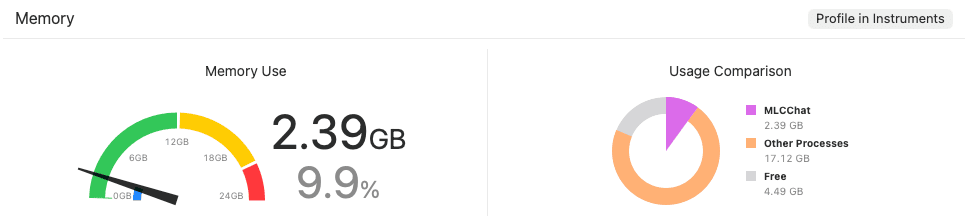 Gemma2 2B q4f16 모델 약 2.4GB의 메모리 점유
Gemma2 2B q4f16 모델 약 2.4GB의 메모리 점유영상을 보시면 On-Device 환경임에도 불구하고 지연 시간(Latency)이 거의 느껴지지 않을 정도로 실시간에 가까운 빠른 응답 속도를 보여주는 것을 확인할 수 있습니다.
커스텀 모델 iOS 빌드하기
기본 모델 외에 원하는 모델을 iOS에 최적화하여 올리는 방법을 소개합니다.
이 과정은ios/MLCChat폴더 밑에서 가상 환경(.venv)이 활성화된 상태를 가정으로 진행됩니다.
모델 다운로드
모델 다운로드를 위해 huggingface_hub를 설치하고 로그인합니다.
1 | pip3 install huggingface_hub --upgrade |
로그인 시 액세스 토큰 입력창이 나타납니다.
1 | ❯ python3 -c "from huggingface_hub import login; login()" |
Hugging Face READ 토큰 발행
- Hugging Face 로그인 후 설정 페이지에서 Access Tokens 메뉴를 선택합니다.
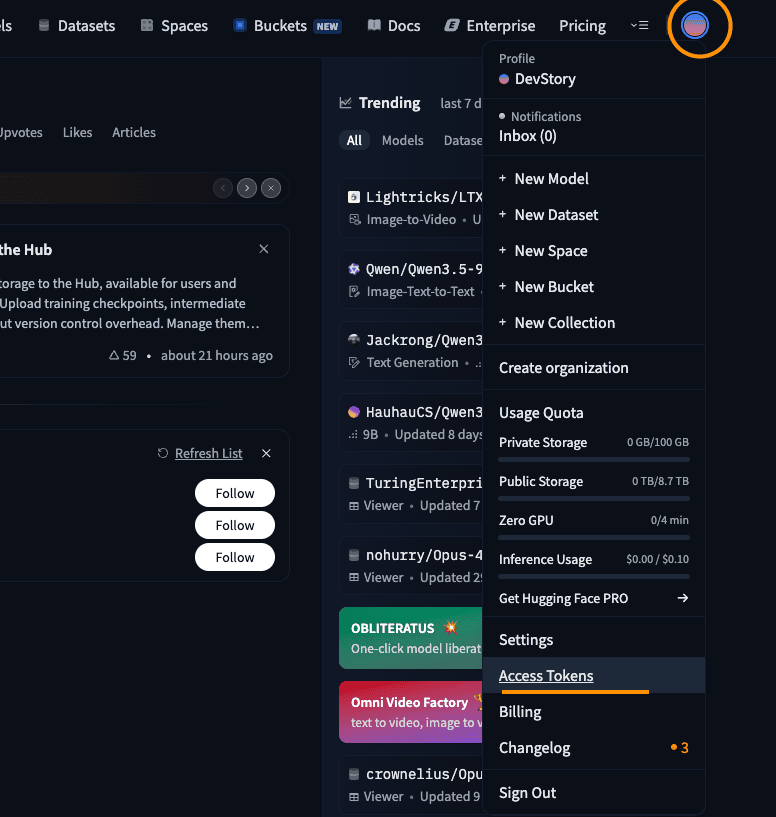 Hugging Face Access Tokens 설정 이동
Hugging Face Access Tokens 설정 이동 - Create new token 버튼을 클릭합니다.
 새 토큰 생성 버튼 클릭
새 토큰 생성 버튼 클릭 - Read 권한을 선택하고 토큰의 이름을 입력한 뒤 발행합니다.
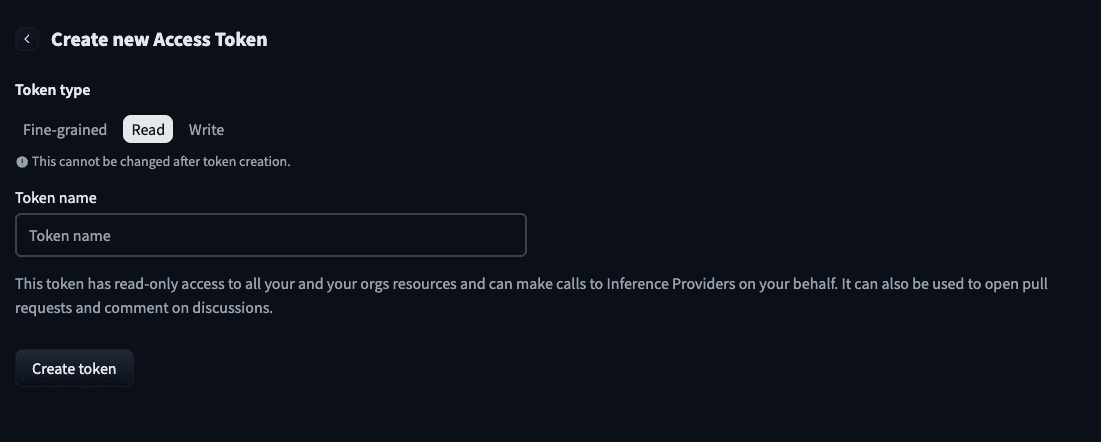 Read 권한 선택 및 이름 입력
Read 권한 선택 및 이름 입력 - 생성된 토큰을 복사하여 터미널에 입력하면 로그인이 완료됩니다.
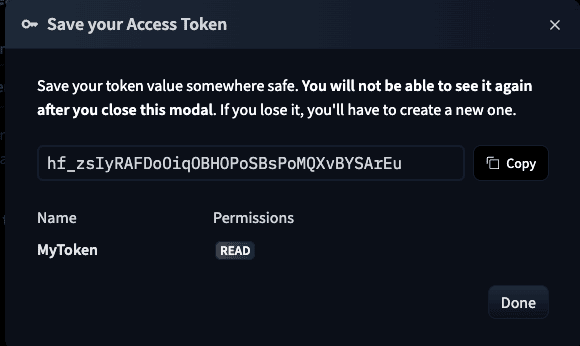 발행된 토큰 복사
발행된 토큰 복사
본 포스팅에서는 Gemma-3-1b-it 모델을 다운받아서 양자화한 뒤 iOS에서 실행해 보겠습니다. 다음 명령어를 실행해 모델을 다운받아 주세요.
1 | python3 -c "from huggingface_hub import snapshot_download; snapshot_download(repo_id='google/gemma-3-1b-it', local_dir='./dist/models/gemma-3-1b-it', local_dir_use_symlinks=False)" |
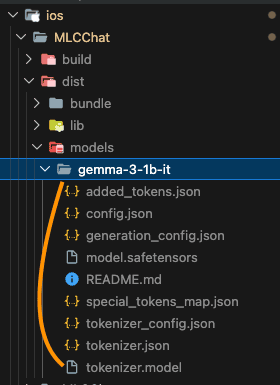 Hugging Face 모델 다운로드 완료
Hugging Face 모델 다운로드 완료명령어 실행시 모델 사용 라이선스에 동의를 하지 않은 경우, 아래와 같이 403 에러가 발생할 수 있습니다.
1 | huggingface_hub.errors.GatedRepoError: 403 Client Error. |
gemma-3-1b-it에 접속해보면 아래와 같이 권한을 수락해야 한다고 나옵니다.
 Hugging Face Gated Repo 권한 필요 메세지
Hugging Face Gated Repo 권한 필요 메세지Kaggle의 Gemma 라이선스 동의 페이지에서 접속하신 뒤, Hugging Face를 선택한 뒤 동의를 진행해 주세요.
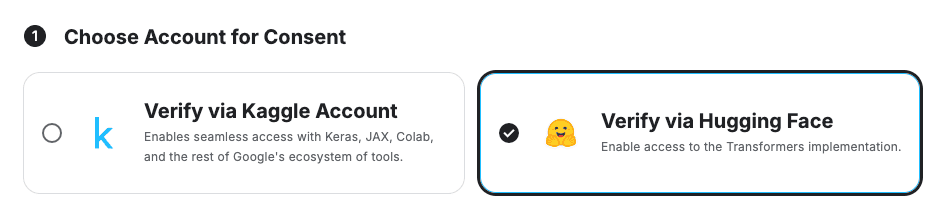 라이선스 동의 진행
라이선스 동의 진행Hugging Face Gated Repos에서 Request Status를 보시면 Accepted 상태로 표시되는 것을 확인할 수 있습니다. 이후 위 명령어를 다시 실행하여 다운로드를 진행하시면 됩니다.
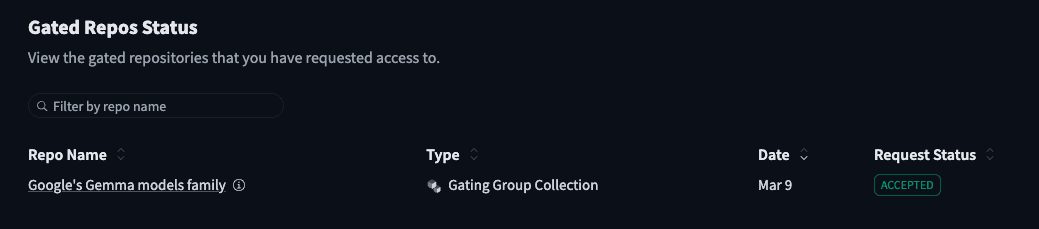 Hugging Face에서 승인된 상태 확인
Hugging Face에서 승인된 상태 확인모델 가중치 변환 및 양자화
Hugging Face에서 다운로드한 원본 safetensors 파일들은 대규모 서버급 GPU에 최적화된 FP16 또는 BF16 포맷입니다. 이를 iPhone의 제한된 RAM에서 실행하기 위해서는 양자화(Quantization) 과정이 필수적입니다. 이 단계에서 MLC-LLM은 가중치를 기기가 이해할 수 있는 작은 조각으로 나누고, 용량을 약 1/4 수준으로 압축하면서도 성능 하락을 최소화하는 작업을 수행합니다.
1 | python3 -m mlc_llm convert_weight ./dist/models/gemma-3-1b-it \ |
 모델 가중치 변환 및 양자화 과정
모델 가중치 변환 및 양자화 과정모델 설정 생성
모델 가중치만으로는 대화가 불가능합니다. 각 LLM마다 ‘어떻게 질문하고 답변해야 하는지’에 대한 약속인 대화 템플릿(Conversation Template)이 다르기 때문입니다. 이 단계에서는 변환된 가중치 폴더 안에 mlc-chat-config.json 등 필요한 설정 파일들을 생성합니다. 특히 Gemma 3 모델의 지시 사항(Instruction)을 정확히 따르기 위해 --conv-template gemma3_instruction 옵션을 지정해야 합니다.
1 | python3 -m mlc_llm gen_config ./dist/models/gemma-3-1b-it \ |
 모델 설정 생성 완료
모델 설정 생성 완료컴파일
마지막으로 최적화된 가중치를 실제로 구동할 실행 엔진(Metal 커널)을 생성하는 단계입니다. 이 과정은 모델의 연산 구조를 iPhone의 GPU(Metal)가 가장 효율적으로 처리할 수 있는 형태의 라이브러리로 변환합니다. device iphone 옵션을 통해 대상 기기의 하드웨어 가속 성능을 최대한 이끌어낼 수 있는 최종 빌드 결과물이 만들어집니다.
1 | python3 -m mlc_llm compile ./dist/models/gemma-3-1b-it-q4f16_1-MLC \ |
 iPhone용 모델 컴파일 완료
iPhone용 모델 컴파일 완료패키징 및 최종 실행
마지막으로 mlc-package-config.json에 새로 빌드한 모델 정보를 추가해야 합니다.
1 | { |
이후 다시 패키징 명령어를 실행해 주세요.
1 | python3 -m mlc_llm package |
패키징 후 Xcode에서 앱을 실행하면 gemma-3-1b-it-q4f16_1 모델이 추가된 것을 확인할 수 있습니다.
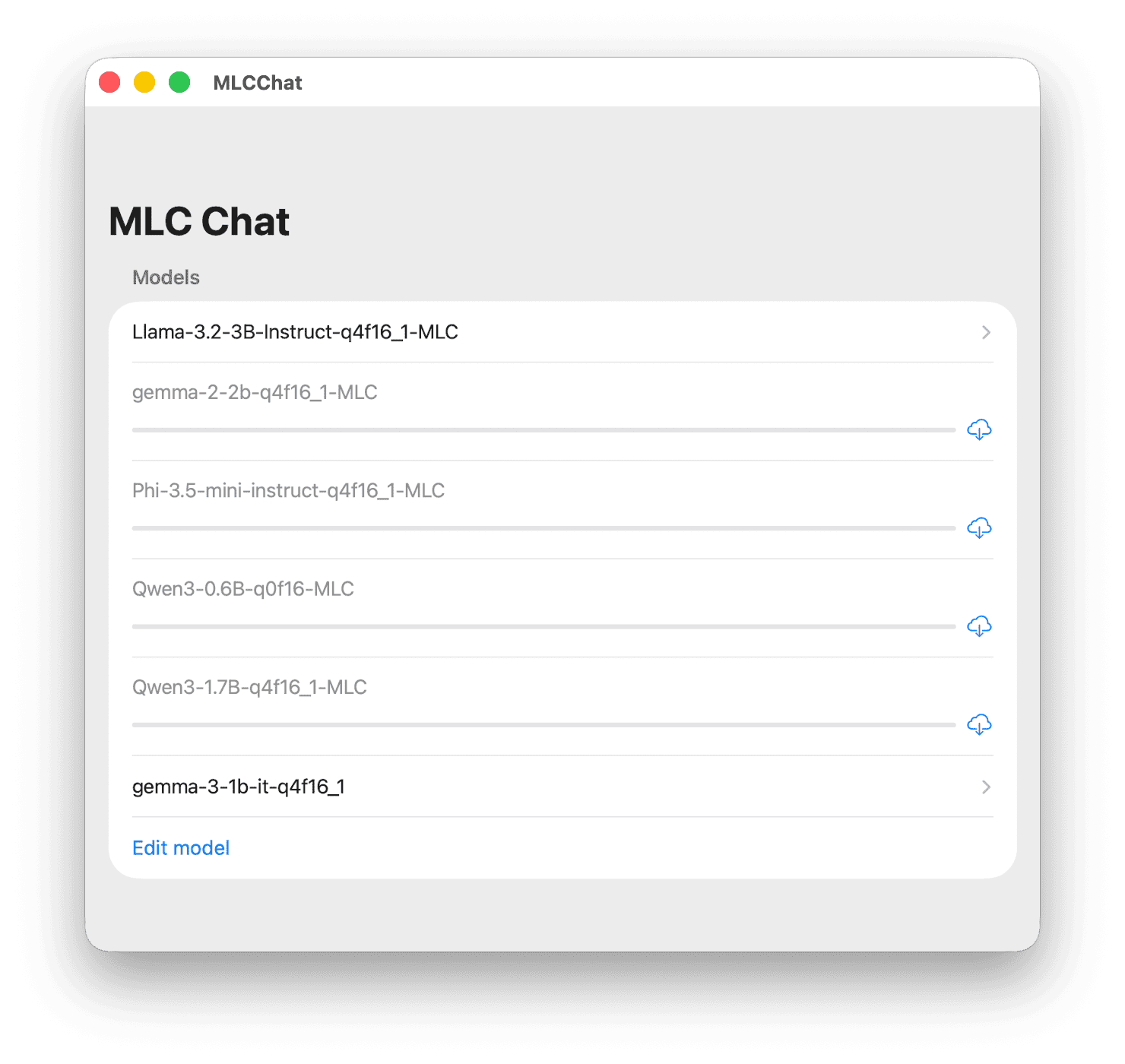 Gemma 3 1B 모델 실행
Gemma 3 1B 모델 실행Gemma 3 1B 모델 실행 데모
Google의 Gemma 3 1B는 앞서 살펴본 2B 모델보다도 더 가볍고 효율적인 10억 개의 파라미터를 갖춘 모델입니다. 최신 아키텍처가 적용되어 크기는 작지만 일상적인 대화나 간단한 태스크에서 놀라운 성능을 보여줍니다.
동일한 q4f16_1 양자화 방식을 적용했을 때, 메모리 점유율은 약 1.14GB 수준으로 대폭 낮아집니다. 이는 구형 기기나 다양한 앱을 동시에 사용하는 환경에서도 모델이 강제 종료되지 않고 훨씬 안정적으로 돌아갈 수 있음을 의미합니다.
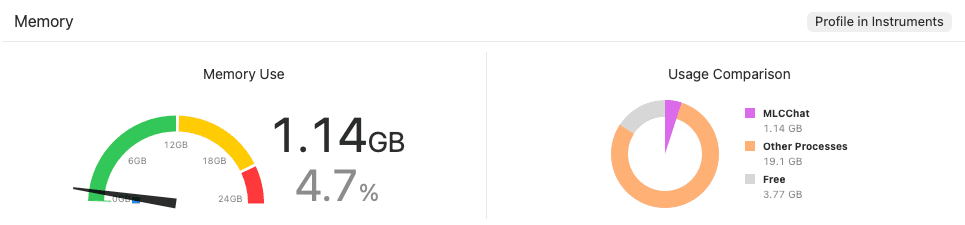 Gemma 3 1B q4f16 모델 약 1.14GB의 메모리 점유
Gemma 3 1B q4f16 모델 약 1.14GB의 메모리 점유마치며
MLC-LLM을 활용하면 고성능 LLM을 iOS 기기에 직접 이식하여 개인 정보 보호와 오프라인 실행이라는 장점을 모두 챙길 수 있습니다.
다만 한 가지 아쉬운 점은, 위에서 시연한 소형 모델(SLM)들은 On-Device 환경에서 JSON 포맷과 같이 구조화된 응답을 생성하는 것을 다소 어려워하는 모습을 보였습니다. 복잡한 시스템 프롬프트가 필요한 기능이나 데이터 추출 업무에 활용하기 위해서는 프롬프트 엔지니어링이나 추가적인 파인튜닝 등의 보완 작업이 수반되어야 할 것 같습니다.
앞으로 모델 전용 파이프라인 연결과 프로젝트 최적화 작업이 병행된다면, 더욱 실용적인 On-Device AI 서비스를 구축할 수 있을 것으로 기대됩니다.